
Written by: Faizy Ahsan
Introduction
Grammatical error correction (GEC) is an important natural language processing (NLP) task when working with text. An automated model that can solve GEC tasks in English is in high demand, especially in proofreading industries, due to the language’s extensive user base. Yet the industrial application of models for GEC tasks faces many crucial challenges, including the collection of suitable data for training, how that training is done, and how correct inferences are made. The traditional approach is to train a suitable model over a corpus of choices; a model is then built using the trained traditional model to make fast predictions on desired texts. In this article, we describe the working of a transformer-based model—a type of attention-based neural network (Vaswani et al. 2017)—to address the GEC problem. We present the results of the transformer-based model fairseq-gec (Zhao et al. 2019) applied to Scribendi datasets. This article aims to provide a foundational understanding of transformer-based GEC models, which will then be explored using model compression techniques in a future article. First, we briefly outline the background of existing computational approaches to the GEC problem. We then describe the Scribendi datasets used in our experiments and the working of transformer models, followed by our evaluation metrics. We conclude with the results of our experiments.
In general, the computational approaches used to address the GEC problem are based on rules, statistical analysis, or neural networks. Significantly, these approaches are not mutually exclusive. A language model, for example, assigns a probability distribution to a sequence of words (Ponte and Croft 1998). When used to address a GEC task, it assumes that a sentence with a low probability score is associated with grammatical errors; the goal is then to modify the sentence so that sentence probability increases (Dahlmeier et al. 2013; Lee and Lee 2014). A rule-based approach, meanwhile, assimilates the syntax of a given sentence and applies rules to tackle specific types of grammatical errors (Sidorov et al. 2013). Statistical machine translation (SMT) aims to translate incorrect sentences into correct ones by combining language models for different factors, such as part-of-speech (POS) tags and lemma (Koehn et al. 2007; Yuan and Felice 2013). Finally, the machine learning (ML) approach applies machine translation models to the GEC task, and state-of-the-art ML GEC models use transformers (see Zhao et al. 2019). However, although transformer-based GEC models have demonstrated remarkable performance, they remain far from achieving human-like levels of correction (Bryant et al. 2019). Moreover, the training time, trained model size, and inference speed of transformer-based GEC models are key impediments to the widespread industrial use of these models.
Datasets
For over 20 years, Scribendi has embraced technology to support the work of editors and writers across the world. The company is now a leader in the online editing and proofreading industry, processing tens of millions of words per month thanks to the work of over 500 editors. This has allowed Scribendi to build a unique dataset that can be used for research on GEC.
For the purpose of this case study, the Scribendi dataset was divided into three sets: training, validation, and testing. Each set consisted of two parts: the original erroneous texts and their corrected counterparts. The numbers of sentences in each set were as follows: 4,790,403 (training), 126,063 (validation), and 126,064 (testing). The mean number of words per sentence in the sets was roughly 18. The minimum and maximum sentence lengths for all sets were 1 and 49, respectively. A sampled subset of 5,000 examples (containing erroneous and corrected versions) was also available as a smaller test set, which was used to evaluate the models in our experiments.
Table 1. GEC Dataset Benchmarks
| Dataset | # of Sentences | Reference |
| Scribendi Train | 4,790,403 | |
| Scribendi Validation | 126,063 | |
| Scribendi Sampled Test | 5,000 | |
| National University of Singapore Corpus of Learner English (NUCLE) | 57,119 | Dahlmeier et al. 2013 |
| Large-Scale Lang8 Corpus | 1,097,274 | Tajiri et al. 2012 |
| First Certificate in English Corpus (FCE) | 32,073 | Yannakoudakis et al. 2011 |
| Johns Hopkins University Fluency-Extended Grammatical/Ungrammatical corpus (JFLEG) | 747 | Napoles et al. 2017 |
| Cambridge English Write & Improve (W&I) + Louvain Corpus of Native English Essays (LOCNESS) | 43,169 | Yannakoudakis et al. 2018 (W&I) Granger 1998 (LOCNESS) |
It is important to note the availability of several other public datasets for GEC research (see Table 1). Apart from the Scribendi sampled dataset, the Conference on Computational Natural Language Learning (CoNLL) 2014 test set, which contains 1,312 sentences, was also used for evaluation in our experiments (Ng et al. 2014). The CoNLL 2014 dataset is derived from the National University of Singapore Corpus of Learner English (NUCLE) dataset (Dahlmeier et al. 2013). The average number of sentences in CoNLL 2014 is 23, and the minimum and maximum sentence lengths are 1 and 227, respectively.
Transformer Network for the GEC Problem
Vaswani et al. (2017) first proposed the transformer network to solve machine learning problems where the inputs are sequences and the outputs can be sequences or a class label (e.g., machine translation, sentiment classification). A transformer network is made up of encoder-decoder architectures along with attention mechanisms without using any recurrent or convolutional architecture. Traditional deep-learning models to solve sequence-related machine learning problems require the input to be fed sequentially, which causes an inherent computational lag (Sutskever et al. 2014). In the transformer network, all inputs can instead be fed in simultaneously: the architecture relies “entirely on an attention mechanism to draw global dependencies between input and output” (Vaswani et al. 2017, p. 2). This enables greater parallelization in the training, faster learning with an increased amount of data, and a lesser impact of increases in sequence length compared to traditional deep-learning models.
The transformer network architecture is shown in Figure 1.

Figure 1. The transformer network architecture (Vaswani et al. 2017).
To train a transformer network for a GEC problem, we require example sentences in grammatically incorrect and correct forms. The first step is to convert the text data into a numerical form so that it can be fed into the transformer network. The typical method of converting text into numerical form is one-hot encoding, in which a matrix is used to record the occurrence or non-occurrence of characters at a particular position in the text. More advanced techniques tokenize the text data, splitting it into tokens that encapsulate the surrounding semantics (Kudo 2018; Sennrich et al. 2015; Schuster and Nakajima 2012). The tokens are then mapped to a vocabulary, and the numerical entries are used as inputs for machine learning models (in this case, the transformer network). It should be noted that the inputs in the encoder or decoder layers are fixed; therefore, the numerical input vector is either trimmed or padded with zeros to match the allowed input size.
The numerical input from a grammatically incorrect sentence is combined with positional embeddings to maintain the order of its elements, and the resulting vectors are fed into the first encoder layer of the transformer. It should be noted that the positional embeddings are used only with the inputs of the first encoder layer: the inputs of the other encoder layers are the outputs of the previous encoder layer. The encoder maintains three weight matrices (W Q, W K , and W V), which are used to compute the attention values of the words in a given sentence. Let xi be the current word in a given sentence with n words. Then, the attention value ai for xi is computed as follows:
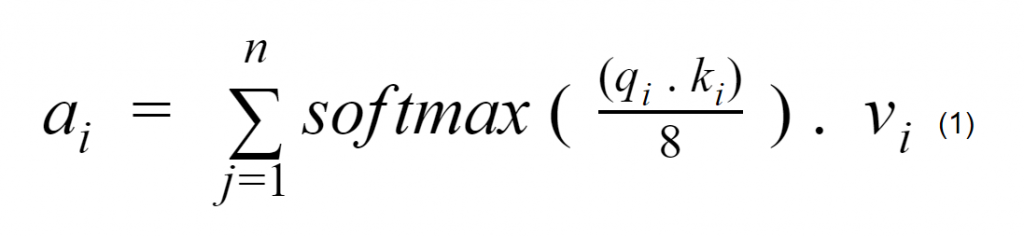
where qi, ki, and vi are the values of the query, key, and value for xi.
The use of query, key, and value vectors to compute the attention of a word is analogous to an information retrieval system whose objective is to respond to a given query with topics based on the most relevant key and value terms. The encoder layer maintains more than one set (usually eight) of query, key, and value vectors to compute multiple attentions for a given word. These multiple attentions are condensed into a single vector, and this is passed to the feed-forward layer after it is added to and normalized with its original input.
The input to the decoder layer is the grammatically correct form of the input sentence with additional <start> and <end> tokens. The goal of the decoder layer is to predict the next token from an input token. Therefore, all the input tokens (except for <end>) are fed into the decoder layer, and the final prediction of the decoder layer should be the <end> token. The dataflow in the decoder layers is like that of the encoder layers, except for an additional masked attention layer so that the next tokens are not considered while computing the attention values; if this masked attention layer is not used, then the decoder layer will not learn to predict the next token. Once the inputs to the decoder layer are passed through the masked attention layer, an attention layer with key and value vectors from the output of the final encoder layer is used to process the incoming data. The final output of the decoder layer is passed through a linear layer whose size is the vocabulary of the training data. The output of the linear layer is passed through a softmax function to obtain the probabilities of each word. The word with the best probability is considered the next word for the given input words to the decoder layers.
The learning of the transformer network is divided into two phases: training and inference. During the training phase, the transformer network parameters are learned. The learned transformer network is then used to predict the grammatically correct form of the given input sentences during the inference phase.
To comprehend the functioning of a transformer network for the GEC problem, consider the following input sentence:
- In a conclusion, there are both advantages and disadvantages of using social media in daily life.
The red words illustrate the grammatical mistakes in the input sentence.
The grammatically correct form of the input sentence is as follows:
- In conclusion, there are both advantages and disadvantages in using social media in daily life.
Now, we need to train the transformer network parameters in the training phase. The input sentence is fed to the encoder portion of the transformer network to produce the encoder output.
Step 1

The encoder output and the grammatically correct form of the input sentence are then fed into the decoder portion.
Step 2

The input sentence to the decoder (i.e., the grammatically correct form) is padded by a <start> token at the initial position and shifted one to the right. The goal of the decoder is to predict the next token for any given token. Because the transformer network is untrained, the decoder output will be incorrect.
Step 3
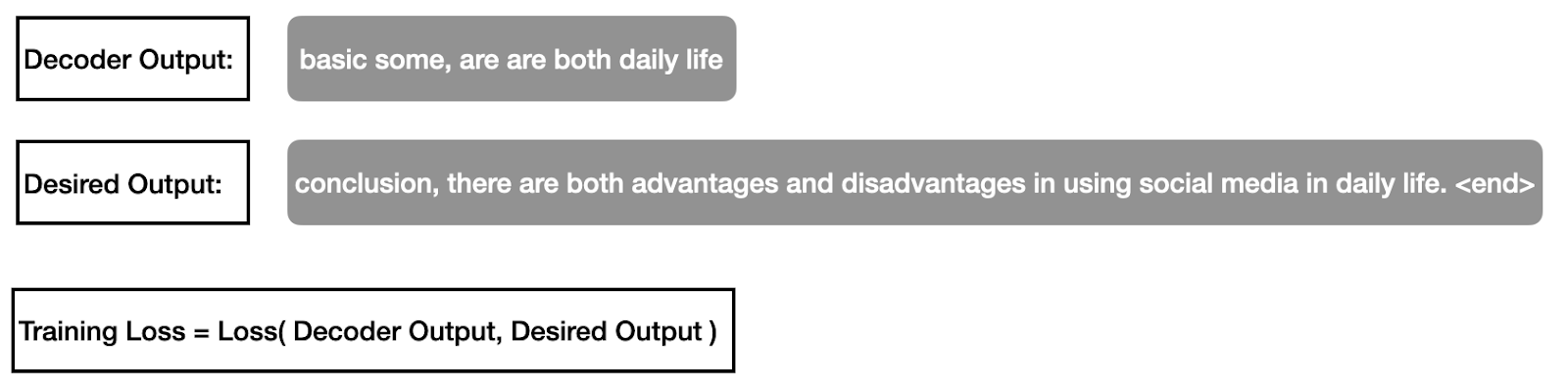
Now, the desired output from the decoder is the grammatically correct form of the input sentence shifted one to the left and padded by an <end> token at the end. The decoder output and the desired output are used to compute a training loss with a suitable loss function (e.g., cross-entropy). The training loss is then back-propagated to train the parameters of the transformer network. In practice, the above process is repeated with millions of sentences.
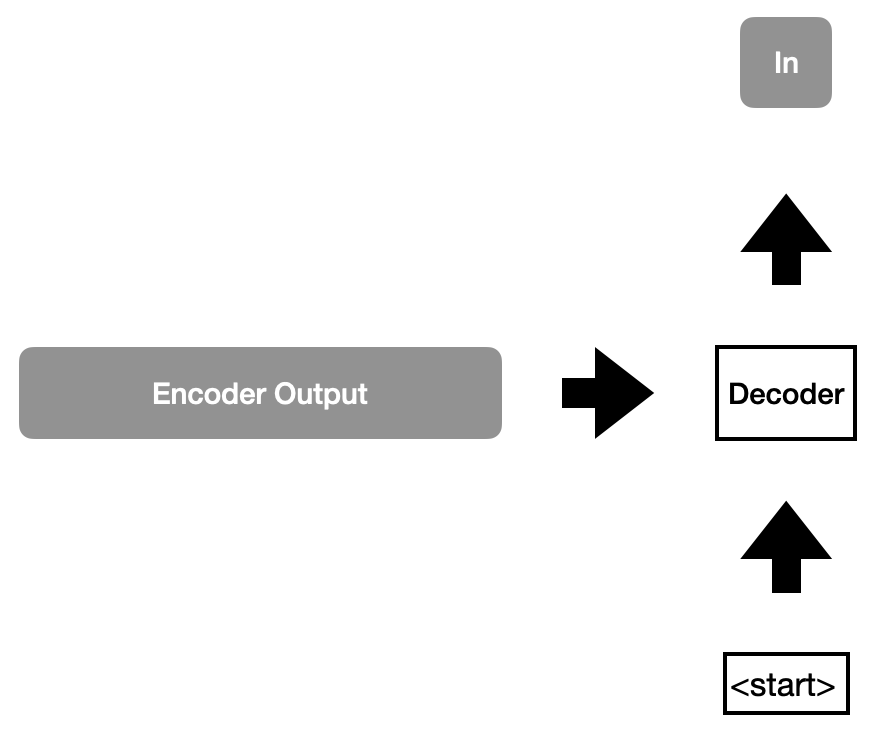
In the inference phase, the encoder step remains the same as in the training phase in which we feed our input sentence into the encoder portion. The encoder output and a <start> token are then fed into the decoder portion. If our transformer network is trained with sufficient accuracy, then the decoder output will be In.
Step 4
Now, the previous decoder output (i.e., In) and the encoder output are fed back into the decoder portion. The decoder should output conclusion.
Step 5
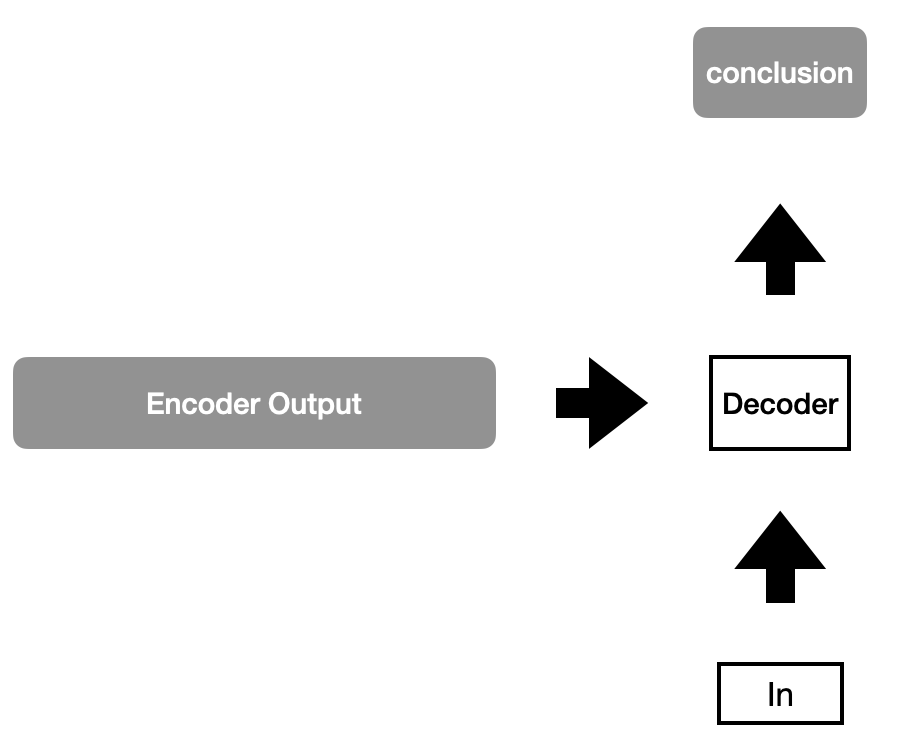
This process is repeated until the <end> token is received from the decoder.
Step 6
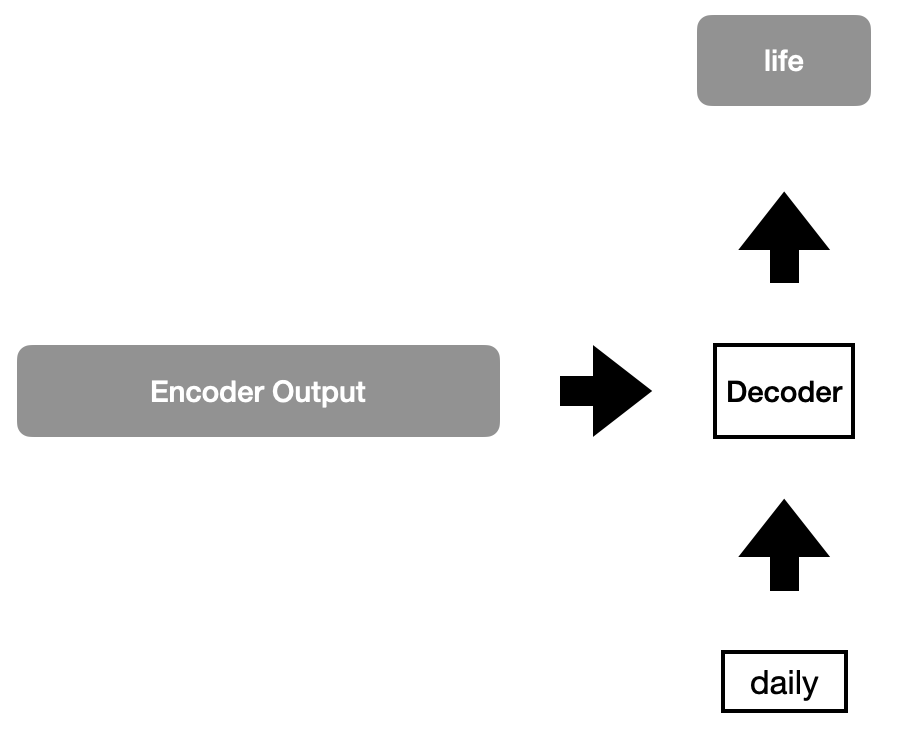
Due to space limitations, we will skip to the processing of the end of the sentence, where the decoder output daily is fed in and receives life as the decoder output.
Step 7
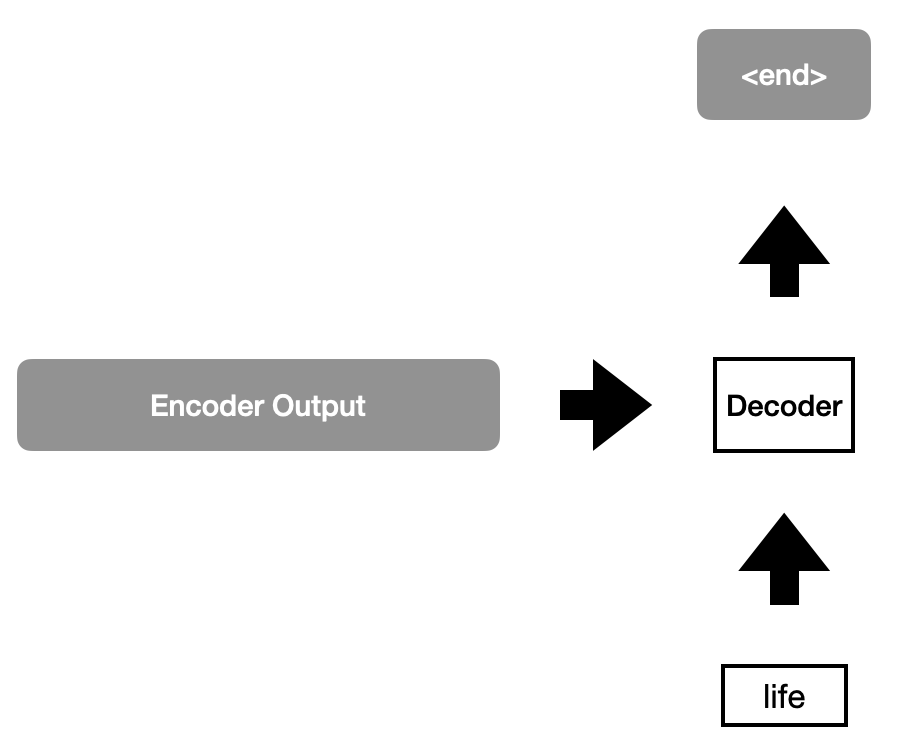
When the decoder output is <end>, the process is stopped, and the decoder outputs the sentence without the <start> and <end> tokens as the transformer network prediction.
To summarize, during training, the words from the grammatically correct sentences are fed into the decoder layers to obtain the next words, and the actual output of the decoder layers is used to compute the training loss. In the inference stage, the input sentence is fed into the encoder layers to obtain the encoder output. The <start> token is then fed into the decoder layers along with the encoder output as key and value vectors. The final decoder layer output will be the probabilities of each word in the target language being the next word. One may either select the word with the maximum probability (greedy search) or maintain the list of top k words as the next possible word (k-beam search) (Freitag et al. 2017). In either case, the output word, along with the <start> token, is fed into the decoder layers along with the encoder output to obtain the next word, and the process is repeated such that the previously predicted words are fed until the <end> token is obtained or the maximum number of iterations has occurred (i.e., the maximum output sentence length is reached).
Metrics
GEC models are commonly evaluated using the following metrics:
- Perplexity—The inverse probability of the sentence, which is normalized by the number of words in the sentence. The lower the perplexity value, the better the model.
- Precision—The number of relevant items identified out of the total claimed relevant items.
- Recall—The number of relevant items identified out of the actual total relevant items.
- F0.5—The harmonic mean of precision and recall, such that recall is weighed lower than precision.
- JFLEG General Language Understanding and Evaluation (JFLEG GLUE)—The collection of datasets and tasks to assess model accuracy for various natural language processing problems (e.g., grammatical mistakes, if sentences are similar) (Napoles et al. 2017).
- Error Annotation Toolkit (ERRANT)—For evaluating GEC models based on error annotations (e.g., detecting verbs, determinant errors) (Bryant et al. 2017).
- Inference Speed—The number of words/sentences predicted by a GEC model in one second.
- Memory Footprint—The file size of a GEC model.
- Train Time—The amount of time required to train a GEC model.
Results and Discussion
To explore the effectiveness of the transformer model in addressing GEC problems, we trained and evaluated the transformer-based GEC model fairseq-gec (Zhao et al. 2019). We chose fairseq-gec for our preliminary experiments because it has been shown to perform better than a basic transformer network on the CoNLL 2014 dataset. Because the ratio of unchanged words is generally high in GEC, the fairseq-gec model focuses mainly on the portion of sentences with changes during the training time. For reference, we compared our experimental results with Scribendi’s sequence-to-sequence-based model (Seq2Seq), which was trained on a Scribendi dataset with 27 million sentences. The training and testing sets in our experiments comprised the Scribendi and CoNLL datasets mentioned above. The evaluation was based on inference speed (measured in words/second), precision, recall, and F0.5 metrics. The experiments in this study were performed on an Ubuntu 16.04 server with Nvidia TITAN X 12 GB GPU, 32 cores, and 126 GB RAM.
In Table 2, we show the results of our experiments with the fairseq-gec model. The fairseq-gec models were not trained until convergence and were sub-optimal compared to Scribendi’s Seq2Seq GEC model. In terms of the training data, the CoNLL training set consisted of 57,119 sentences, and the Scribendi training set consisted of 4,790,403 sentences. For the test data, the CoNLL test set contained 1,331 sentences; the Scribendi test set contained 126,064 sentences.
Table 2. Experiments with fairseq-gec
| Model | Training Data | # of Training Epochs | Training Time (days) | Test Data | Inference Speed | Precision, Recall, and F0.5 |
| 1. Scribendi Seq2Seq | 27 million | 17 | 6 | CoNLL 2014 Testing Set | 3667.00 | 0.65 0.35 0.55 |
| 2. Fairseq-gec | CoNLL 2014 Training Set | 22 | 2 | CoNLL 2014 Testing Set | 420.37 | 0.46 0.27 0.40 |
| 3. Fairseq-gec | CoNLL 2014 Training Set | 22 | 2 | Scribendi Testing Set | 244.51 | 0.07 0.07 0.07 |
| 4. Fairseq-gec | Scribendi Training Set | 15 | 4 | Scribendi Testing Set | 199.25 | 0.1 0.1 0.1 |
| 5. Fairseq-gec | Scribendi Training Set | 30 | 5.7 | CoNLL 2014 Testing Set | 238.06 | 0.31 0.18 0.27 |
| 6. Fairseq-gec | CoNLL 2014 + Scribendi Training Sets | 9 + 30 | 5.9 | CoNLL 2014 Testing Set | 185.01 | 0.33 0.25 0.31 |
We observed from our experiments that the fairseq-gec model can adequately address the GEC problem. However, its accuracy was much lower for the Scribendi test set than the CoNLL 2014 test set. Scribendi’s Seq2Seq model (crucially, not a transformer network) was found to be the best performing model across the six experiments. The Seq2Seq model was trained on a far larger dataset with comparatively high computational resources. It would therefore be interesting to compare Seq2Seq model performance with a transformer network that was trained with a similarly sized dataset and with comparable computational resources. More detailed notes for each of the six experiments are given in the Appendix (Table 1).
In this article, we have described how the GEC problem can be addressed through transformer-based models. In our next article in this series, we will experiment with state-of-the-art transformer GEC models and explore model compression techniques as a means of enhancing inference speed with a comparatively lower negative impact on evaluation metrics.
References
Bryant, Christopher, Mariano Felice, Øistein E. Andersen, and Ted Briscoe. 2019. “The BEA-2019 Shared Task on Grammatical Error Correction.” In Proceedings of the 14th Workshop on Innovative Use of NLP for Building Educational Applications, Florence, Italy, August 2019, 52–75. Association for Computational Linguistics. doi:10.18653/v1/W19-4406.
Bryant, Christopher, Mariano Felice, and Ted Briscoe. 2017. “Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction.” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, July 2017, 793–805. Association for Computational Linguistics. doi:10.18653/v1/P17-1074.
Dahlmeier, Daniel, Hwee Tou Ng, and Siew Mei Wu. 2013. “Building a Large Annotated Corpus of Learner English: The NUS Corpus of Learner English.” In Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications, Atlanta, Georgia, June 2013, 22–31. Association for Computational Linguistics. https://www.aclweb.org/anthology/W13-1703.
Freitag, Markus, and Yaser Al-Onaizan. 2017. “Beam Search Strategies for Neural Machine Translation.” arXiv preprint arXiv:1702.01806.
Granger, Sylviane. 1998. “The Computer Learner Corpus: A Versatile New Source of Data for SLA Research.” In Learner English on Computer, edited by Sylviane Granger. Routledge.
Koehn, Philipp, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondřej Bojar, Alexandra Constantin, and Evan Herbst. 2007. “Moses: Open Source Toolkit for Statistical Machine Translation.” In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic, June 2007, 177–180. Association for Computational Linguistics. https://www.aclweb.org/anthology/P07-2045.
Kudo, Taku. “Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates.” arXiv preprint arXiv:1804.10959.
Lee, Kyusong, and Gary Geunbae Lee. 2014. “POSTECH Grammatical Error Correction System in the CoNLL-2014 Shared Task.” In Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task, Baltimore, Maryland, June 2014, 65–73. Association for Computational Linguistics. doi:10.3115/v1/W14-1709.
Napoles, Courtney, Keisuke Sakaguchi, and Joel Tetreault. 2017. “JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction.” In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, Valencia, Spain, April 2017, 229–234. Association for Computational Linguistics. https://www.aclweb.org/anthology/E17-2037.
Ng, Hwee Tou, Siew Mei Wu, Ted Briscoe, Christian Hadiwinoto, Raymond Hendy Susanto, and Christopher Bryant. 2014. “The CoNLL-2014 Shared Task on Grammatical Error Correction.” In Proceedings of the 18th Conference on Computational Natural Language Learning: Shared Task, 2014, 1–14.
Ponte, Jay M. and W. Bruce Croft. 1998. “A Language Modeling Approach to Information Retrieval.” In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 1998, 275–281.
Schuster, Mike, and Kaisuke Nakajima. 2012. “Japanese and Korean Voice Search.” In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2012, 5149–5152.
Sennrich, Rico, Barry Haddow, and Alexandra Birch. 2015. “Neural Machine Translation of Rare Words with Subword Units.” arXiv preprint arXiv:1508.07909.
Sidorov, Grigori, Anubhav Gupta, Martin Tozer, Dolors Catala, Angels Catena, and Sandrine Fuentes. 2013. “Rule-Based System for Automatic Grammar Correction Using Syntactic N-Grams for English Language Learning (L2).” In Proceedings of the Seventeenth Conference on Computational Natural Language Learning: Shared Task, 2013, 96–101.
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. 2014. “Sequence to Sequence Learning with Neural Networks.” Advances in Neural Information Processing Systems 27: 3104–3112.
Tajiri, Toshikazu, Mamoru Komachi, and Yuji Matsumoto. 2012. “Tense and Aspect Error Correction for ESL Learners Using Global Context.” In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Jeju Island, Korea, July 2012, 198–202. Association for Computational Linguistics. https://www.aclweb.org/anthology/P12-2039.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention is All You Need.” In Advances in Neural Information Processing Systems 30: 5998–6008.
Yannakoudakis, Helen, Øistein E. Andersen, Ardeshir Geranpayeh, Ted Briscoe, and Diane Nicholls. 2018. “Developing an Automated Writing Placement System for ESL Learners.” Applied Measurement in Education 31: 251–267.
Yannakoudakis, Helen, Ted Briscoe, and Ben Medlock. 2011. “A New Dataset and Method for Automatically Grading ESOL Texts.” In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, June 2011, 180–189. Association for Computational Linguistics. https: //www.aclweb.org/anthology/P11-1019.
Yuan, Zheng and Mariano Felice. 2013. “Constrained Grammatical Error Correction Using Statistical Machine Translation”. In Proceedings of the 17th Conference on Computational Natural Language Learning: Shared Task, Sofia, Bulgaria, August 2013, 52–61. Association for Computational Linguistics. https://www.aclweb.org/anthology/W13-3607.
Zhao, Wei, Liang Wang, Kewei Shen, Ruoyu Jia, and Jingming Liu. 2019. “Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, June 2019, 156–165. Association for Computational Linguistics. doi:10.18653/v1/N19-1014.
Appendix
Table 1. Experiment Notes
| Experiment # | Notes |
| 1 | The model used was a sequence-to-sequence model with attention built with four encoders and four decoders. It used byte-pair encoding to select a vocabulary of 50,000 sub-word units. It was trained with four GPUs with 27 million sentences; the training took around 2.5 weeks. |
| 2 | The model was a transformer network with a copying mechanism that transfers unchanged words from the input to the output for more effective processing (Zhao et al. 2019). The idea behind this experiment was to replicate the results shown in Zhao et al. (2019) for the CONLL-2014 dataset without investing too much computational time and resources. However, the model was trained with default parameters and was stopped before the training converged due to the high computational requirements. |
| 3 | The model was fairseq-gec trained on the CONLL-2014 dataset but tested on the Scribendi dataset. The idea was to check the efficiency of the model trained on a different corpus than that used for training. The poor results indicated that the model needs further training and that the features present in the CONLL-2014 dataset may be insufficient for building a proper model that could detect grammatical mistakes in addition to the Scribendi dataset. |
| 4 | The fairseq-gec model was trained and tested on the Scribendi datasets. The slight improvement in the results showed that the model was able to grasp the grammatical mistakes present in the Scribendi dataset. A greater amount of training should therefore yield an even better model. |
| 5 | The fairseq-gec model was trained on the Scribendi dataset for a longer duration. In this experiment, we trained the model on the Scribendi dataset but evaluated it on the CONLL-2014 dataset. Although the training was incomplete, the resulting model was much better than those in experiments 2 and 3. Moreover, the results showed that it was possible to train the fairseq-gec model on one corpus and apply the trained model to a different corpus. It should be noted that the size of the Scribendi training dataset (4,790,403) was significantly larger than its CONLL-2014 equivalent (57,119). Thus, if we must test a model on a different corpus, a large magnitude of training data is needed. In future experiments, we will explore the number of training examples required to build a robust model that works well on a different corpus (i.e., a corpus that was not used for training). |
| 6 | The fairseq-gec model was trained on both the CONLL-2014 and Scribendi training datasets and evaluated on the CONLL-2014 dataset. The accuracy measurements were better than those for the model in experiment 5, as the model was trained using the grammatical mistakes present in both the CONLL-2014 and Scribendi datasets. |
About the Author

Faizy Ahsan is a Ph.D. student in computer science at McGill University. He is passionate about formulating and solving data mining and machine learning problems to tackle real-world challenges. He loves outdoor activities and is a proud finisher of the Rock ‘n’ Roll Montreal Marathon.