
The problem
Scribendi provides high-quality editing and proofreading for writers around the world to ensure that their ideas are communicated clearly and effectively. Writers can submit their editing orders through Scribendi’s website. These orders vary in type (e.g., business versus academic), length, complexity, and urgency (the client decides the turnaround time). Once an order is placed, it becomes available to Scribendi’s network of professional freelance editors. Freelance editors have no obligation to take on an order; therefore, Scribendi needs to monitor all orders to ensure that they are completed on time. This process is managed by an editorial department coordinator, called the Duty Editor.
Before creating the order queuing tool, Scribendi required Duty Editors to use their experience, as well as some available metrics (e.g., time remaining until the deadline, number of words in the document), to identify potential late orders and take action to ensure the orders were completed on time. However, this created several problems, as Duty Editors
- gave different priorities to metrics based on their experience and may not have evaluated orders in the same way;
- were not able to continuously and systematically evaluate each new order in relation to all other outstanding orders, especially since they were also performing other tasks during the day;
- may have had behavioral biases, which were likely to affect their decisions. There is strong evidence supporting the claim that default choices matter.1 For example, a non-prioritized list may still be treated as an ordered list (“I have to start somewhere, so I might as well start from the top”), which means that orders that are lower down on the list may be missed or given lower preference, even if they have a higher risk of being late; and they
- were not always aware of which freelancers were available at a given time or of freelancers’ specializations and preferences.
Therefore, the aim of the order queuing tool is to prioritize outstanding orders in a systematic way to lower the number of late orders, which ensures that students and academics can submit their work on time, businesses meet their deadlines, and blogs and opinions are published without delay.
The solution
The project built an order queuing tool based on a machine learning algorithm. The tool has two main components. The first evaluates the probability of an order being late based on its initial characteristics, which are known immediately at the time of submission on the website. It includes details like the time of order, the order type, the word length, and the price. Based on these characteristics, a machine learning model, which leverages Scribendi’s experience, determines the probability of an order being late and provides the initial ranking of orders.
The second component provides a real-time update of orders based on freelance editor behavior and other parameters, like the time until the deadline. The ranking tool is therefore a weighted combination of the initial probability and the real-time parameters, with the weighting assessment favoring real-time parameters. This means that the probability of an order being late gives the initial ranking, but this probability receives less importance as new information becomes available. For example, the time left to complete the order constantly changes, influencing the order priority.
The details: Predicting the probability of an order being late
The model was built using a dataset of roughly 160,000 orders from January 2016 to July 2018. The features that were created using the dataset can be grouped into three broad categories, which are a mix of continuous and discrete features:
- Time of order features, such as the time until the deadline, the month (to address seasonality), and whether an order is due during periods of low freelancer engagement.
- Type of order features, such as the document type (e.g., academic or business), the starting quality of the document, the format of the file to edit, and the word count.
- Price and payment features, such as freelancer pay.
The dataset is highly unbalanced. Only 2.6% of the orders in the dataset were returned late, and many of the late orders were concentrated in the few days when demand spiked. The problem faced here is similar to anomaly detection efforts, like classifying bank fraud, medical problems, or text errors, which aim to identify rare observations. This rate is even lower once large, longer-term orders like manuscripts are excluded (deadlines on these orders are often extended by the client to give the editor extra time to deal with ad hoc requests).
The first task of the tool is therefore a classification problem, but instead of being interested in the final classification (e.g., “Will Order #123456 be late?”), we are interested in the probability of an order being late relative to all the other outstanding orders (more on this comparison later). We encountered several challenges with this approach. All models achieved high accuracy, since even a simple rule like “the order is always on time” has 97.4% accuracy. Despite this high accuracy, the models had low precision2 (the classifier labelled many “not late” observations as “late”) and low recall3 (the classifier could not correctly identify all the late observations).
This is a common problem in anomaly detection and there are several techniques to address the effects of an unbalanced dataset. These include oversampling the minor class, under-sampling the major class, a combination of both, or synthetically creating new minor samples. The performance of these techniques is task specific, depending on the type of data and the size of the dataset. In our case, under-sampling worked best, as is often the case when applied to larger datasets. This means that we created a new dataset with all the ‘late’ observations and only a subsample of the ‘not late’ observations. Many ratios were tested, but a 1:1 ratio of ‘late’ to ‘not late’ gave the best performance.
Once the balanced dataset was created with the full feature set, it was easy to apply several algorithms4: logistic regression, random forest, support vector machines, stochastic gradient descent, and even a simple neural network were used on the data. This is where some trade-offs emerged. More complex algorithms may offer better predictive capabilities, but also come at a cost, particularly in terms of explainability (i.e., understanding the functioning of the algorithm) and ease of implementation. For example, if we were using a multi-layer perceptron model, it may require a separate server and possibly a queue in the middle during prediction. Thus, while the performance of this model would be similar to logistic regression, the implementation of the model would require a more complex setup which includes multiple instances. Furthermore, the task is not a prediction problem, which would generally favour these algorithms. Instead, the aim is to find the probability of an order being late relative to all the other outstanding orders. For this project, ranking is more important than prediction.
This gives logistic regression an edge over the other algorithms considered. It offers comparable performance metrics, but also includes interpretability because the impact and the sign of each feature on the probability of being late is known from the coefficients. This is important, as it gives Scribendi valuable information on which order characteristics matter (at the very least, it confirms some initial hypotheses). The transparency of logistic regression offers another advantage: ease of implementation, as its output offers a simple formula to evaluate any new order. A logistic regression model can also handle the mix of continuous and discrete independent variables. These characteristics make logistic regression one of the most used machine learning algorithms when it comes to binary classification. Claudia Perlich, an Adjunct Professor at NYU, argues that if the signal-to-noise ratio is low (as is the case in anomaly detection), logistic regression is likely to perform better than decision tree-based models. She also argues that logistic regressions might be better at ranking and estimating probability when compared to decision tree-based models5, which may give greater accuracy6.
A final consideration for the model is how to deal with time. Scribendi’s orders fluctuate depending on the time of year. For example, many academic submissions occur in December, January, and May. To address these times, dummies (based on months) were used. However, this is a noisy measure; a busy period may be the last week of a month and the first week of the next month. Similarly, some public holidays also are correlated with demand spikes. Splitting the data into busy and not-busy datasets also did not improve the results (and introduced additional complications). Instead, the project split the train, test, and validation sets by day. While this does not model the seasonality, it ensures that the results are not due to the test or validation set over- or under-sampling a particularly busy period. This is arguably an area that can be more effectively dealt with as data regarding the impact of the tool becomes available.
The details: Real-time updating
After identifying the traits of late orders at the time they were placed, we had to focus on updating their prioritization once we could observe how the community of freelance editors behaves.
This is mostly a work in progress; however, we can think about two major categories:
- Actions that can be observed, such as the approaching deadline, or the fact that freelance editors do not accept a specific order;
- Company priorities and guidelines. These are rules that translate the internal experience into automated actions, such as discriminating the evaluation of internal orders and client orders, or isolating types of documents that routinely behave in a different way (e.g., PDF or LaTeX documents are not as easy to edit as a standard MS Word document).
The result of this analysis is a set of rules and exceptions that alter the initial scoring to keep the prioritization current. This set of rules is evolving as the Scribendi teams gets more familiar with the mechanism.
Finally, we always leave the option open for the Duty Editor to reprioritize orders using a simple drag and drop interface. This might open up opportunities to collect data for optimizing the tool using reinforcement or online learning.
Putting the tool into production
Thanks to the fact that the tool leveraged a regression algorithm, we were able to implement a solution that can dramatically improve our operations under pressure, without incurring major financial investments, service disruptions, or additional and significant complexity to the infrastructure.
It is also easier to update and understand rules (e.g., add more factors that influence either the initial score or the real-time updating), and to maintain the algorithm, as there are no additional external components (like virtual machines or queuing tools) being introduced in the system.
This view gives an idea of the Duty Editor interface we implemented to manage the tool,
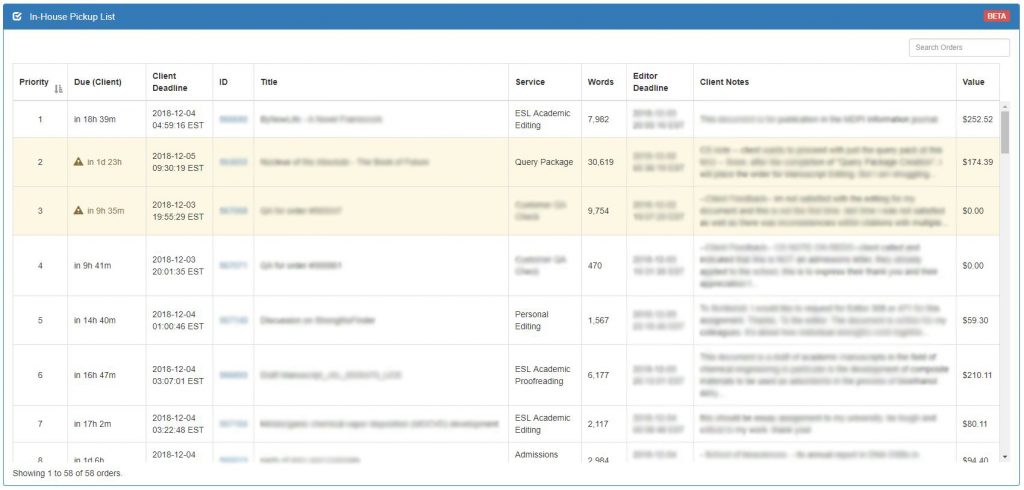
while the following image shows its implementation on the back-end, where we see the interaction between the initial probability algorithm and the real-time updates.
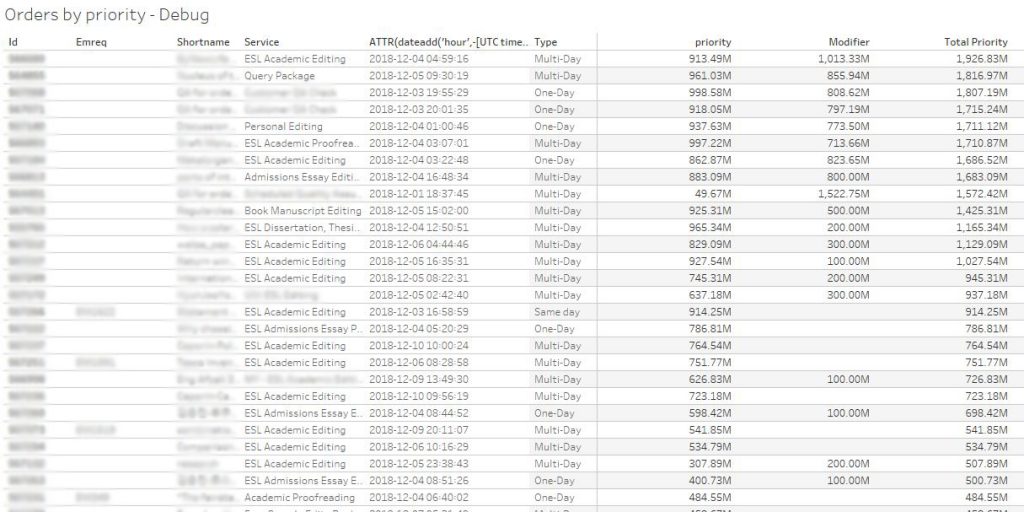
Some final thoughts
Our approach was to keep the tool as simple as possible. It is sometimes tempting to use more complex or newer algorithms without considering their costs. The logistic regression is a straightforward and effective model7 and offers additional insights from interpreting the coefficients. Splitting the tool into two steps was also driven by simplicity. The first step gives a static assessment of the order when it is submitted which is combined in the second step with real-time updates. Each component in the second step is weighted in terms of importance. This makes the evaluation process more transparent and easier to implement and update (by tweaking the weights in the second step or recalculating the first step). This has provided a smoother path to implementation, avoiding the fate of many machine learning projects being perennially stuck in pre-implementation phases.
The final part of the project will be to monitor the effectiveness of the tool. Feedback from the Duty Editors on how they use it, and whether it aligns with their experience in identifying problematic orders, will be important. Ultimately, the main test of the tool will be whether it leads to fewer late orders. To find that out, you’ll have to watch this space!1
1For example, see Johnson and Goldstein (2003) on default choices in organ donation, Halpern et al. (2013) on default choices in healthcare, and Benartzi and Thaler(2004) on default choices in saving for retirement.
2A refresher: precision is True Positives /(True Positives + False Positives).
3Recall is True Positives / (True Positives + False Negatives).
4Although some additional data pre-processing was needed, depending on the algorithm requirements
5Perlich, P., Provost,F., and Simonoff, J. 2003. Tree Induction vs. Logistic Regression: A Learning-Curve Analysis. Journal of Machine Learning Research 4: p211-255.
6https://www.forbes.com/sites/quora/2017/06/19/what-are-the-advantages-of-logistic-regression-over-decision-trees/#3aa4822c3524
7Once you establish its underlying assumptions hold.
About the Author
Martin has extensive experience in analysing and drafting economic policy, with focus on industrial policy, incentive design, and localizing mining benefits. Some of his work can be found here and here. He has recently stepped into the world of data science, dusting off knowledge from his M.Sc. in Mathematical Economics and Econometric Methods from Tilburg University (the Netherlands) and combining it with an intensive data science bootcamp from Thinkful.com. Away from the computer, Martin can be found training for his next marathon with equal amounts of fear and excitement. For a full bio, see his LinkedIn profile.