
Transfer learning is a machine learning technique in which a model is trained to solve a task that can be used as the starting point of another task. Deep Learning (p. 256) describes transfer learning as follows:
"Transfer learning and domain adaptation refer to the situation where what has been learned in one setting … is exploited to improve generalization in another setting."
Transfer learning works well for image-data and is getting more and more popular in natural language processing (NLP). Caffe Model Zoo has a very good collection of models that can be used effectively for transfer-learning applications. For image-classification tasks, there are many popular models that people use for transfer learning, such as:
For NLP, we often see that people use pre-trained Word2vec or Glove vectors for the initialization of vocabulary for tasks such as machine translation, grammatical-error correction, machine-reading comprehension, etc.
Transfer learning is useful for saving training time and money, as it can be used to train a complex model, even with a very limited amount of available data. Recently, Google published a new language-representational model called BERT, which stands for Bidirectional Encoder Representations from Transformers. BERT uses a bidirectional encoder to encapsulate a sentence from left to right and from right to left. Thus, it learns two representations of each word—one from left to right and one from right to left—and then concatenates them for many downstream tasks. It is impossible, however, to train a deep bidirectional model as one trains a normal language model (LM), because doing so would create a cycle in which words can indirectly see themselves and the prediction becomes trivial, as it creates a circular reference where a word’s prediction is based upon the word itself. This is an oversimplified version of a mask language model in which layers 2 and actually represent the context, not the original word, but it is clear from the graphic below that they can see themselves via the context of another word (see Figure 1).
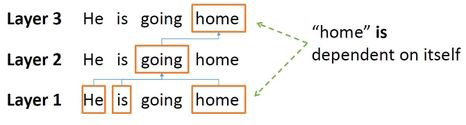
Figure 1: Bi-directional language model which is forming a loop.
In BERT, authors introduced masking techniques to remove the cycle (see Figure 2).
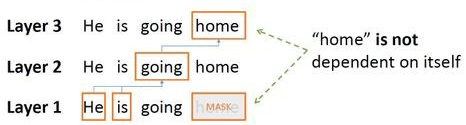
Figure 2: Effective use of masking to remove the loop.
BERT’s authors tried to predict the masked word from the context, and they used 15–20% of words as masked words, which caused the model to converge slower initially than left-to-right approaches (since only 15–20% of the words are predicted in each batch). Still, bidirectional training outperforms left-to-right training after a small number of pre-training steps.
The authors trained a large model (12 transformer blocks, 768 hidden, 110M parameters) to a very large model (24 transformer blocks, 1024 hidden, 340M parameters), and they used transfer learning to solve a set of well-known NLP problems. They achieved a new state of the art in every task they tried.
After the experiment, they released several pre-trained models, and we tried to use one of the pre-trained models to evaluate whether sentences were grammatically correct (by assigning a score). In the paper, they used the CoLA dataset, and they fine-tune the BERT model to classify whether or not a sentence is grammatically acceptable.
We used a PyTorch version of the pre-trained model from the very good implementation of Huggingface. It is possible to install it simply by one command:
pip install pytorch_pretrained_bert
We started importing BertTokenizer and BertForMaskedLM:
from pytorch_pretrained_bert import BertTokenizer,BertForMaskedLM
import torch
import pandas as pd
import math
We modelled weights from the previously trained model. If you did not run this instruction previously, it will take some time, as it’s going to download the model from AWS S3 and cache it for future use. The available models for evaluations are:
- bert-base-uncased
- bert-large-uncased
- bert-base-cased
- bert-base-multilingual
- bert-base-chinese
From the above models, we load the “bert-base-uncased” model, which has 12 transformer blocks, 768 hidden, and 110M parameters:
bertMaskedLM = BertForMaskedLM.from_pretrained('bert-base-uncased')
Next, we load the vocabulary file from the previously loaded model, “bert-base-uncased”:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
Once we have loaded our tokenizer, we can use it to tokenize sentences. We need to map each token by its corresponding integer IDs in order to use it for prediction, and the tokenizer has a convenient function to perform the task for us. We convert the list of integer IDs into tensor and send it to the model to get predictions/logits. We use cross-entropy loss to compare the predicted sentence to the original sentence, and we use perplexity loss as a score:
def get_score(sentence):
tokenize_input = tokenizer.tokenize(sentence)
tensor_input = torch.tensor([tokenizer.convert_tokens_to_ids(tokenize_input)])
predictions=bertMaskedLM(tensor_input)
loss_fct = torch.nn.CrossEntropyLoss()
loss = loss_fct(predictions.squeeze(),tensor_input.squeeze()).data
return math.exp(loss)
We load our dataset from a CSV file:
data = pd.read_csv('NER_2.csv')
# we are selecting columns and renaming them
df = pd.DataFrame(data, columns=["Unnamed: 0","2","3","4"]).rename(columns={"Unnamed: 0":"src", "2":"model1", "3":"model2", "4":"tgt"})
np_array = df.values
The language model can be used to get the joint probability distribution of a sentence, which can also be referred to as the probability of a sentence. By using the chain rule of (bigram) probability, it is possible to assign scores to the following sentences:
P("He is go to school")=P(He)*p(is|he)*p(go|is)*p(to|go)*p(school|to)=0.008
P("He is going to school")=0.08
We take a peek at our dataset:
print(np_array[0])
array(['All author have seen the manuscript and approved to submit to your journal .',
'All authors have seen the manuscript and approved to submit to your journal .',
'All authors have seen the manuscript and have been approved to submit to your journal.',
'All authors have seen the manuscript and approved it to be submitted to your journal .'],
dtype=object)
We can use the above function to score the sentences. As we are expecting the following relationship—PPL(src)> PPL(model1)>PPL(model2)>PPL(tgt)—let’s verify it by running one example:
for j in range(1):
print(j, [get_score(i) for i in np_array[j]])
# [5.6603, 3.5675, 3.5233, 3.1202]
That looks pretty impressive, but when re-running the same example, we end up getting a different score. Thus, the scores we are trying to calculate are not deterministic:
for j in range(1):
print(j, [get_score(i) for i in np_array[j]])
# [8.5432, 5.3421, 3.4543, 6.4345]
This happens because one of the fundamental ideas is that masked LMs give you deep bidirectionality, but it will no longer be possible to have a well-formed probability distribution over the sentence.
The scores are not deterministic because you are using BERT in training mode with dropout. If you set bertMaskedLM.eval() the scores will be deterministic.
Hello, Ian. Thanks for checking out the blog post. Yes, there has been some progress in this direction, which makes it possible to use BERT as a language model even though the authors don’t recommend it. I will create a new post and link that with this post.
Hi! Did you ever write that follow-up post? I do not see a link.
Thanks,
Adam
Thanks for very interesting post.
I’m also trying on this topic, but can not get clear results.
Thank you for the great post.
So we can use BERT to score the correctness of sentences, with keeping in mind that the score is probabilistic.
This is a great post. Did you manage to have finish the second follow-up post?
There is a similar Q&A in StackExchange worth reading.
https://datascience.stackexchange.com/questions/38540/are-there-any-good-out-of-the-box-language-models-for-python
Where and how can we use these scores?
Hi
Thank you for checking out the blogpost. You can use this score to check how probable a sentence is. When text is generated by any generative model it’s important to check the quality of the text. We can use PPL score to evaluate the quality of generated text