
Written by: Ankit Vadehra, Asadul Islam, and Pascal Poupart
Grammar error correction (GEC) tools have become increasingly popular in recent years. While grammar is typically domain independent, the more general tasks of text editing and proofreading are domain dependent since some expressions may need to be revised according to the topic, genre, and style of the document. Hence, we ask the following question: Do existing GEC tools used for text editing generalize well across domains? To answer this, we tested the generalization ability of three representative GEC models on eight datasets.
To achieve state-of-the-art results, GEC models often use data augmentation and tags. Given this, we tested the model by Kiyono et al. (2019) and the grammatical error correction: tag, not rewrite (GECToR) model by Omelianchuk et al. (2020) as representative models that focus on data augmentation and the usage of tags, respectively. As a baseline, we also tested a vanilla transformer encoder–decoder of six layers based on the architecture originally proposed by Vaswani et al. (2017). Note that the goal of the evaluation was not to determine the best model per se (there is already a leaderboard that ranks GEC models based on two popular benchmarks) but rather to examine whether the performance of these models on unseen datasets is comparable to their performance on the datasets used for their development.
Since most public datasets are fairly small (tens of thousands of sentence pairs), augmenting the data with up to 200 million artificially created sentence pairs helps boost model performance tremendously (Stalhberg et al., 2021). Techniques inspired by back-translation are often used for data augmentation by creating erroneous sentences from clean sentences. There are two important classes of GEC models: sequence2sequence models and techniques that iteratively tag and correct tokens. Sequence2sequence models typically use a transformer-based encoder–decoder architecture that resembles the architecture used by machine translation. Below, we test a vanilla transformer encoder–decoder as a baseline. The advantage of this architecture is that it is available off the shelf in several libraries; however, training and inference are slow. In contrast, techniques that iteratively tag and correct tokens are lighter and therefore much faster to train and use in practice (e.g., inference with GECToR is 10x faster than transformer-based sequence2sequence models). This speed increase is due to the use of only an encoder (i.e., no decoder). The encoder embeds source sentences, and based on this, a classifier is used to tag and possibly correct each token. Therefore, inference is reduced to classification (instead of text generation).
Over the years, steady progress has been made on several GEC benchmarks. A leaderboard for the CoNNL14 and BEA19 datasets summarizes the performance achieved by the best GEC models developed by the community. However, development using the same data risks overfitting the benchmarks over time. To improve the state of these benchmarks, researchers have developed techniques that exploit their properties. For instance, tags are often designed to maximize the coverage of the errors encountered in the benchmarks. Similarly, Stahlberg et al. (2021) showed that data augmentation yielded the best improvement when synthetically generated data matched the statistics of the benchmarks. Below, we test the three GEC models based on six benchmarks commonly used to develop existing models and two new datasets.
Table 1: Dataset properties. Datasets 1–6 are common benchmarks often used to develop models. Datasets 7 and 8 are new datasets assembled for this evaluation.
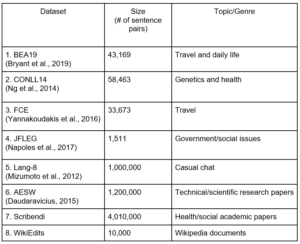
The Scribendi dataset is a new private dataset from Scribendi. It includes four million sentence pairs, primarily from health and social science academic papers. The WikiEdits dataset is a novel dataset derived from WikiAtomicEdits by filtering out edits unlikely to correspond to a form of grammar error correction (e.g., the addition of new information or rephrasing). More precisely, edits that changed the sentence length by more than 20% (i.e., a corrected sentence that had 20% more or fewer words) were filtered out. Furthermore, to make sure that an edit is unlikely to change the meaning of a sentence, we filtered out edits that did not yield the same translation in German as the source. Finally, edits that changed only capitalization and the trailing period were filtered out.
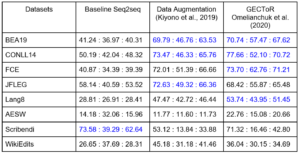
Table 2 compares the ERRANT Precision, Recall, and F1 scores achieved by the three GEC models on the eight datasets. For each model, we highlighted in blue the scores of the datasets used to train and/or test it. Since these datasets were used by the researchers to develop the model, their properties were often exploited; therefore, the scores tended to be higher for them than for the datasets not used to develop the model. Note that we colored the results for the datasets used for testing in blue even though the algorithms could not directly exploit the properties of these datasets during training. Instead, researchers may repeatedly conduct model testing using these datasets until they obtain good results, thereby indirectly exploiting the properties of the test datasets. We observed that for each model, the scores of the blue datasets tended to be higher than those of the non-blue datasets. This is not surprising given that, in practice, any dataset is divided into training and testing subsets. The model is fine-tuned on the training part and tested on the testing part, so we would expect that the model would perform well on similar data. However, when someone uses a GEC tool to edit a document, there is no guarantee that the document is similar to any of the datasets used to train the model utilized by the tool. Hence, there is a need for a greater degree of generalization across topics, genres, and styles.
Table 2: ERRANT Precision:Recall:F1 scores. For each model, scores highlighted in blue indicate that the corresponding dataset was used to develop the model.
References
Bryant, C., Felice, M., Andersen, Ø. E., & Briscoe, T. 2019. “The BEA-2019 Shared Task on Grammatical Error Correction.” In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, 2019, 52-75.
Daudaravicius, V. 2015. “Automated Evaluation of Scientific Writing: AESW Shared Task Proposal.” In Proceedings of the Tenth Workshop on Innovative Use of NLP for Building Educational Applications, 2015, 56-63.
Kiyono, S., Suzuki, J., Mita, M., Mizumoto, T., & Inui, K. 2019. “An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, 1236-1242.
Mizumoto, T., Hayashibe, Y., Komachi, M., Nagata, M., & Matsumoto, Y. 2012. “The Effect of Learner Corpus Size in Grammatical Error Correction of ESL Writings.” In Proceedings of COLING 2012: Posters, 2012, 863-872.
Napoles, C., Sakaguchi, K., & Tetreault, J. 2017. “JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction.” In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 2017, 229-234.
Ng, H. T., Wu, S. M., Briscoe, T., Hadiwinoto, C., Susanto, R. H., & Bryant, C. 2014. “The CoNLL-2014 Shared Task on Grammatical Error Correction.” In Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task, 2014, 1-14.
Omelianchuk, K., Atrasevych, V., Chernodub, A., & Skurzhanskyi, O. 2020. “GECToR–Grammatical Error Correction: Tag, Not Rewrite.” In Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, 2020, 163-170.
Rei, M., & Yannakoudakis, H. 2016. “Compositional Sequence Labeling Models for Error Detection in Learner Writing.” In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, 1181-1191.
Stahlberg, F., & Kumar, S. 2021. “Synthetic Data Generation for Grammatical Error Correction with Tagged Corruption Models.” In Proceedings of the 16th Workshop on Innovative Use of NLP for Building Educational Applications, 2021, 37-47.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. 2017. “Attention is All You Need.” In Advances in Neural Information Processing Systems, 30, 2017, 5998-6008.